Dear MySQLers, the Cloud Is Good, But the Fog Is the Next Big Thing

And here we go again: here is another term. We are still debating about the real meaning of Cloud and if a database fits in IaaS, PaaS, SaaS or in a combination of all three, and now we experience another wave of change.
To be fair, the term Fog Computing has been around for quite some time, but it has never enjoyed the popularity of its buddy “the Cloud”.
Is Fog Computing another pointless renaming of well known technologies and IT infrastructures? Or is it a real new thing that Systems and Database Administrators should look at, study and embrace? My intent here is not to support one side or the other, but simply to instil a few thoughts that may turn handy in understanding where the IT market is going, and more specifically where MySQL can be a good fit in some of the new trends in technology.
IoT: Internet of Things? No! IT + OT
When we talk about IoT in general, everyone agrees that it is already changing the world we are living in. Furthermore, analysts predict trillions of dollars in business for IoT, and clearly all the big high-tech companies want a large slice of the pie. Things become interesting though when we ask analysts, decision makers and engineers what is IoT, or even better, what is the implementation of IoT. The thought goes immediately to our wearables, smart phones, or devices at home: smart fridges and smart kettles are embarrassing examples of something that looks like the new seasonal fashion trend. These devices are certainly a significant part of IoT, they make ordinary people aware of IoT, but they are not what developers and administrators should [only] look at. The multi-trillion$ business predicted by analysts is a mix of smart devices that can connect together cities and rural areas, homes and large buildings, offices and manufacturing plants, mines, farms, trains, ships, cars… but also goods and even animals and human beings. All these connected elements have one thing in common: they generate a massive amount of data. This data must be collected, stored, validated, moved, analyzed… and this is not a trivial job.
Many refer to IoT as Internet of Things, but also at IIoT as Industrial Internet of Things, i.e. to this part of IoT that is related to an industrial process. In industrial processes, we add more complexity to the equation: the environment is sometimes inhospitable, intermittently accessible and unattended by operators and users (or there are literally no users). All this may also be true for non IIoT environments, the difference is that if your Fitbit runs out of power you may be disappointed, but if a sensor on an oil platform or an actuator on a train does not have power, that may be a bigger deal.
To me, IoT is clearly all of the above, with IIoT being a subset of IoT. Personally, I have a particularly different approach to IoT. In almost my entire working life I have been involved in the IT (i.e. Information Technology) side of the business, recently with databases, but previously designing and building CRM and ERP products and solutions. In my mind IoT means IT meets OT (i.e. Operational Technology) and the two technologies cannot be treated separately: they are tightly related and any product in IoT has an IT and an OT aspect to consider. It also means that OT is no longer relegated to the industrial and manufacturing world of PLC and SCADA systems, and is now widely adopted in any environment and at any level, even in what we wear or implant.
The convergence of IT and OT into IoT makes IT physical, something that has been missing in many IT solutions. We, as IT people dealing with data, tend to manage data in an abstract manner. When we consider something physical, we refer to the performance we can squeeze from the hardware where our databases reside. With OT, we need to think broadly ofthe physical world where the data come from or go to and, even more importantly, of the journey of that data in every bit of the IT and OT infrastructure.
It’s a Database! No, It’s a Router! No, It’s Both!
The journey! That is the key point. MySQLers think about data as data stored into a database. When we think about the movement of data, we refer to it in terms of data extraction or data loading. The fact is, in IoT, data has value and it must be treated and considered when stored somewhere (data at rest) and when moving from one place to another (data in motion). Moving data in IoT terms means data streaming. There are a plethora of solutions for streaming, like Kafka, RabbitMQ and many other *MQ products, but their main focus is to store and forward data, not to use it while it is in motion. The problem is, infrastructures are so complicated, with multiple layers and with too many cases where data stops while in motion, that it becomes a priority to analyse and “use” the data even when it is transiting from one component to another.
This is a call to build the next generation database, optimised for IoT, with features that go beyond the ability to store and analyse data. Data streaming and analysis of streamed data must be part of a modern database, as also highlighted by a recent Gartner report. If you are a Database Administrator, you may consider it a database with all the features of a traditional database, but with routing and streaming capabilities. If you are a Network and Systems Administrator you may consider it a router or a streaming system with database capabilities. In a way or another, the database needed for IoT must incorporate the features of a traditional database and the ones of a traditional router. Furthermore, it must take into consideration all the security aspects of data moved and stored multiple times and, even more importantly, it must provide a safe data attestation (but let’s reserve this aspect for another post).
Welcome to Fog Computing
So, here it is: Fog Computing is all of the above. Take three layers:
- The Edge: where things, animals and human beings live where data is collected, or where results from analysis go.
- The Cloud: where a massive amount of data is stored and analysed, where systems are reliable and scalable, and are attended by operators and administrators.
- The Fog: is everything in between. It is, in oriental terms, “where the ground meets the sky”. The Fog is the layer that is still closed to the Edge, but must provide features that are typically associated to the Cloud. It is also the layer where data is collected from a vast amount of things, and is consolidated and sent to the Cloud whenever it is possible.
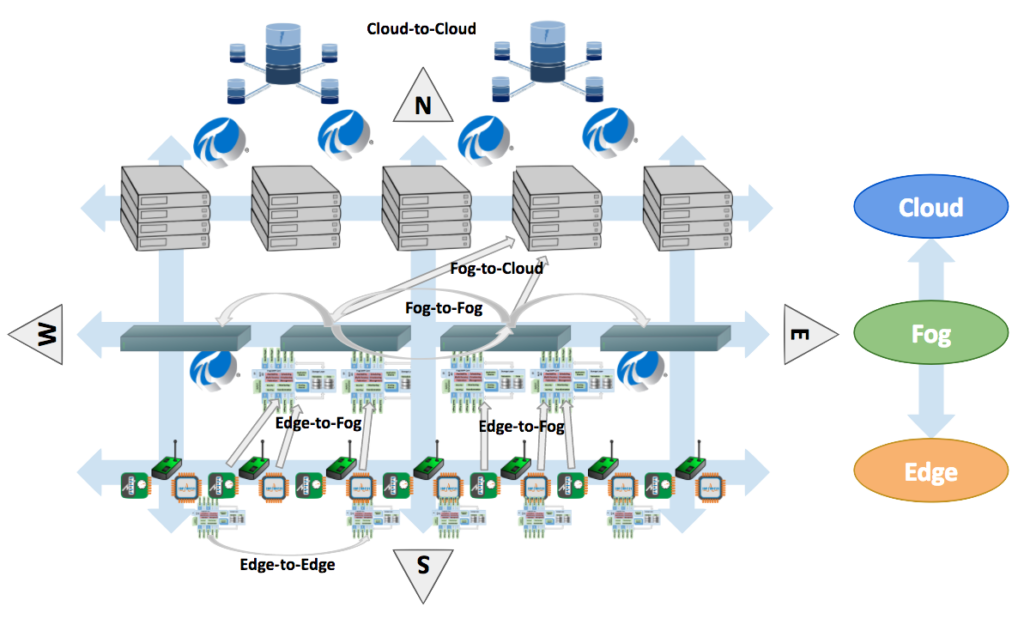
The term Fog Computing is so vague that for some analysts it refers to everything from the Edge of sensors and devices to regional concentrators, routers and gateways. For other analysts, Fog Computing refers only to the layer above the Edge, ie. to the gateways and routers. Personally, I like to think that the former, i.e. Edge + middle layer, offers a more practical definition of Fog Computing.
In Fog Computing, we bring the capabilities of Cloud computing into a more complex, constrained and often technically inhospitable environment. We must collect and store a large amount of data on constrained devices the size of a wristwatch, where the processing power is mostly used to operate the system and the data management is a secondary aspect. Although the power of an Edge system is increasing exponentially, we no longer have the luxury of a stable, always-on environment. It is a bit like going back 20 years or more, when we started using personal computers to manage data. It is a fascinating challenge, certainly unwelcome by lazy administrators, which brings excitement to experienced developers.
Where Is MySQL in All This?
Here is the catch: Fog Computing desperately needs databases. Products that can handle data at rest and in motion, on constrained devices, with a small footprint, databases that can maximise the use of hardware resources, are reliable and can be installed in many flavours to be almost 100% available when needed. Many NoSQL solutions are good in theory (because of the the way they manage unstructured data), but they are often too resource-hungry to compete in this environment, or they lack features that MySQL has implemented more than a decade ago. Embedded databases are on the other side of the offer, but their features are often limited, making the solutions pretty incomplete.
Sounds familiar? Edge and Fog Computing are the perfect place for MySQL, or at least for solutions based on MySQL, where more features must be added. At the moment there are no real database and data management products for Fog Computing. The current solutions are mostly based on MySQL, but they are built ad hoc and their implementation is non replicable: a situation that slows the growth of this market, making the overall cost of a solution higher than it should be.
The opportunity is huge, but also challenging. The first implementation does not have to be a new fresh product, it can be something achievable, step by step. As for more examples and real, live projects, watch this space!